How Machine Learning is Enhancing Natural Language Processing
Get link
Facebook
X
Pinterest
Email
Other Apps
Message from the blogger:
Greetings, Dear readers;
"My name is Punya Prasoon Panda, currently pursuing BTech,Computer Science and Engineering, from Lovely professional University, India
Pursuing engineering as a career was never my desire; I wanted to be a doctor, but failing the admission exam for a government college with 30 marks crushed my dreams.
But then the subject of Computer Science and Coding piqued my interest, and a desire to learn something new emerged within me, prompting me to alter my field of interest to something that had been passed down through decades on my paternal side, thereby carrying on the legacy.
the blog which i am writing is my current interest and want to share my findings and analytics that "How Machine learning is enhancing Natural Language Processing", hope you readers enjoy gaining experiences from this blog".
What is Machine Learning:
A subfield of computer science and artificial intelligence called machine learning (ML) is concerned with using data and algorithms to help AI mimic human learning processes and progressively become more accurate.
How does ML work?
A machine learning algorithm is divided into three major elements.
Decision Process:Machine learning algorithms are commonly employed to predict or classify data. Based on some input data, which can be labeled or unlabeled, your algorithm will generate an estimate about a pattern.
Error function:An error function evaluates the model's predictions. If known examples exist, an error function can compare them to determine the model's accuracy.
Model Optimization Process:
If the model fits better to the data points in the training set, the weights are modified to lessen the difference between the known example and the model prediction. The algorithm will repeat this iterative "evaluate and optimize" procedure and updates weights autonomously until a threshold of accuracy has been met.
What is Natural Language Processing:
A machine learning technique called natural language processing (NLP) enables computers to understand, manipulate, and interpret human language. Large amounts of text and speech data are now being collected by organizations via a variety of communication channels, including emails, text messages, social media newsfeeds, audio, video, and more. They automatically process this data, evaluate the message's intent or sentiment, and react to human communication in real time using natural language processing (NLP) software.
How does NLP work?
Natural language processing (NLP) is a combination of computational linguistics, machine learning, and deep learning models that process human language.
Computing linguistics:
Computational linguistics is the study of human language models using computers and software technologies. Researchers employ computational linguistics tools, such as syntactic and semantic analysis, to develop frameworks that assist robots in understanding conversational human language. Language translators, text-to-speech synthesizers, and speech recognition software all rely on computational linguistics.
Machine learning:
Machine learning is a technique for improving the efficiency of a computer by training it on sample data. Sarcasm, metaphors, variances in sentence structure, and grammatical and usage exceptions are all elements of human language that humans must learn throughout time. Programmers utilize machine learning approaches to teach NLP systems to analyze and accurately understands these features from the start.
Deep Learning:
Deep learning is a subfield of machine learning that trains computers to learn and think like humans. It employs a neutral network made up of data processing nodes designed to simulate the human brain. Deep learning enables computers to detect, categorize, and correlate complex patterns in incoming data.
Knowing The Topic
Natural language processing (NLP) has become a part of our daily lives. It now plays a crucial role in simplifying once-time consuming tasks. A perfect example is sending a voice command to a smartphone, a virtual home assistant, or even a car to get a task done. Voice-enabled tools, including popular ones like Google Assistant, Alexa, and Siri, all use NLP and machine learning (ML) to function properly
In general, natural language includes human communication, such as how people speak and how words are utilized in everyday life. However, understanding natural language is a difficult problem for robots since a variety of factors influence how humans communicate with one another and their surroundings. The rules are limited and fragmentary, and they can change based on the language and dialect, the context of the discourse, and the relationship between people speaking.
NLP employs machine learning to help a machine comprehend how humans communicate with one another. It also uses datasets to build tools that understand the syntax, semantics, and context of a given interaction. Today, NLP powers much of the technologies we use at home and businesses.
Machine learning utilizes learning models to command its understanding of human language. It is based on a learning framework that lets computers train themselves on input data. ML can use a wide range of models to process data to facilitate better understanding. It can interpret standard and unusual inquiries. And because it can improve continually from experience, it can also handle edge cases independently without being reprogrammed.
Main Topic Relation Between NLP and ML
There is frequently uncertainty about the relationship between machine language and natural language processing. ML can be used in NLP technology, however there are other types of NLP that do not rely on AI or ML. A excellent example is an NLP tool that is intended to extract fundamental facts. It may rely on systems that do not require continuous learning through AI. However, for more complex applications of machine learning NLP, systems can employ ML models to improve their understanding of genuine speech. ML models can also help you adjust to changes in human language over time. Meanwhile, NLP applications can be powered by unsupervised machine learning, supervised machine learning, both, or none, in conjunction with other systems.
Machine learning, when employed in natural language processing, may recognize patterns in human speech, comprehend sentient context, detect contextual hints, and learn any other component of text or voice input. More complicated applications that demand high-level comprehension to engage in understandable conversations with humans necessitate the use of machine learning.
Machine learning for NLP consists of a number of arithmetic systems that identify various portions of speech, sentiment, entities, and other text features. These systems can take the form of a model that can be applied to different sets of text, a process known as supervised machine learning. In addition to being a model, systems can be a collection of algorithms that work across vast datasets to extract meaning in what is known as unsupervised machine learning.
!!! When working with NLP in machine learning, it is critical to understand the primary differences between supervised and unsupervised learning. This makes it easier to get the most out of both in one system !!!.
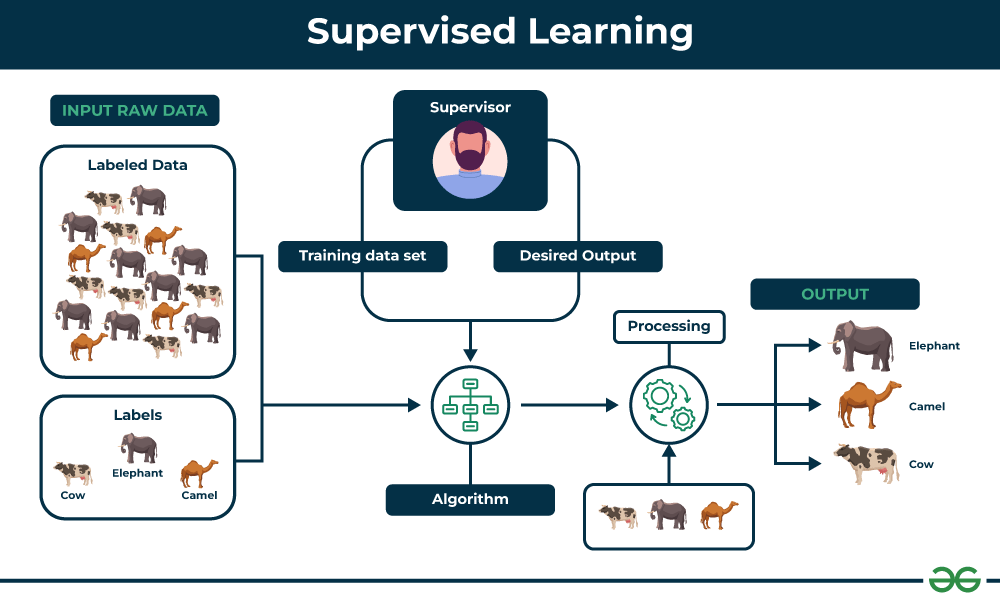
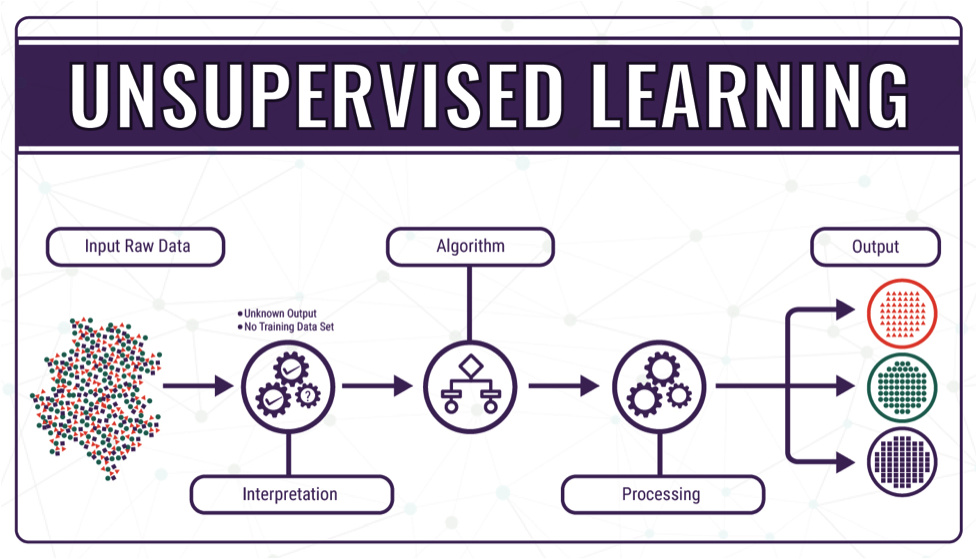
Supervised And Unsupervised Machine Learning
Supervised Machine Learning For NLP
In supervised ML, a large volume of text is annotated or tagged with examples of what the system should search for and how to understand it. These texts are used to train a statistical model, which is given untagged text to examine. Later, larger or better datasets may be utilized to retrain the model as it learns more about the text it studies. For example, you may use supervised machine learning to train a model to analyze film or TV show reviews and then teach it to include each reviewer's star rating.
It is critical that the data or information provided into the model be accurate and clean. This is because supervised machine learning requires high-quality input to deliver the desired outcomes. With sufficient training, tagged data is put into the model, and the machine examines and assesses the text based on what it has learned from the examples.
!!! This type of NLP machine learning use statistical models to enhance its comprehension. It grows more exact over time, and data scientists may expand the textual material that the system reads as it learns. However, this ML use case faces certain difficulties in understanding edge situations since machine learning NLP in this context is highly reliant on statistical simulations!!!.
The most popular supervised NLP machine learning algorithms are:
Support Vector Machines
Bayesian Networks
Maximum Entropy
Conditional Random Field
Neural Networks/Deep Learning
Approach to Supervised Machine Learning
The precise approaches used by data scientists to train machines vary from one application to another, but the following are the main methods:
1)Categorization and Classification
Categorization is the process of classifying stuff into buckets to provide a rapid, high-level overview of what is in the data. To train a text classification model, data scientists utilize pre-sorted information and gently guide it until it achieves the required degree of accuracy. As a consequence, text documents are accurately and reliably classified in a fraction of the time and energy that human analysis would need.
2)Named Entity Recognition
Named entities are persons, locations, and objects (products) described in a written document. Unfortunately, entities can include hashtags, emails, mailing addresses, phone numbers, and Twitter handles. In fact, if you look at things correctly, almost anything may be considered a creature. And don't get us started on tangential allusions.
# It’s also important to note that named entity recognition models rely on accurate PoS tagging from those models.
3) Part of Speech Tagging
Part of Speech labeling (PoSt) entails recognizing each token's part of speech (noun, adverb, adjective, etc.) and then labeling it accordingly. PoSt is the foundation of a lot of critical Natural Language Processing jobs. We must accurately identify parts of speech in order to detect entities, extract themes, and process sentiment.
4) Sentiment Analysis
Sentiment analysis is the process of detecting if a piece of writing is positive, negative, or neutral before providing a weighted sentiment score to each entity, subject, topic, and category in the text.
This is a highly difficult activity that changes greatly depending on circumstance.
For example, take the phrase, “Clash of Clans” In the context of game
It would be difficult to write a set of NLP rules that account for every potential emotion score for every possible phrase in every possible circumstance. However, by training a machine learning model on pre-scored data, it may learn to distinguish between "Clash of Clans" in the context of gaming and other sources.
Unsurprisingly, each language need its own sentiment categorization algorithm.
5) Tokenization
Tokenization is the process of breaking down a written document into machine-readable components, such as words. You're probably very proficient at distinguishing between words and nonsense. English is really easy. Notice all the white space between the letters and paragraphs? That makes it very simple to tokenize. Therefore, NLP principles are sufficient for English tokenization.
But how can one teach a machine learning system what a word looks like? What if you aren't dealing with English-language documents? Logographic languages, such as Mandarin Chinese, do not use whitespace.
This is where we use machine learning to tokenization. Chinese, like English, has rules and patterns that we can teach a machine learning model to recognize and interpret.
Unsupervised Machine Learning For NLP
Unsupervised machine learning entails training a specific model without annotation or pre-tagging. This form of ML can be hard, but it requires far less data and work than supervised ML.
Approach to Unsupervised Machine Learning
1) Clustering
Clustering refers to the grouping of comparable documents into groups or sets. These groups are then ordered according to significance and relevance.
2) Latent Semantic Indexing (LSI)
Another sort of unsupervised learning is Latent Semantic Indexing (LSI). This approach discovers words and phrases that commonly appear together. Data scientists use LSI for faceted searches or to offer search results that do not match the specific search word.
The phrases "manifold" and "exhaust" are closely associated in literature about internal combustion engines. So, when you Google "manifold," you get results that include "exhaust."
3) Matrix Factorization
Matrix Factorization is another approach to unsupervised NLP machine learning. This technique employs "latent factors" to convert a huge matrix into two smaller matrices. Latent factors are the commonalities between objects.
Consider the line, "I threw the ball over the mountain." The term "threw" is more commonly linked with "ball" than with "mountain". In fact, humans have a natural ability to understand the factors that make something throwable. But a machine learning NLP algorithm must be taught this difference.
Using Machine Learning on Natural Language Sentences
Machine learning models excel at detecting entities and overall sentiment in a document, but they fail to extract themes and subjects and are ineffective at matching sentiment to particular entities or themes.
Alternatively, you may train your system to recognize the fundamental laws and patterns of language. In several languages, a proper noun followed by the word "street" likely refers to a street name. Similarly, a number followed by a proper noun followed by the word "street" most often indicates a street address. People's names often follow standard two- or three-word formulations for proper nouns and nouns.
Unfortunately, documenting and applying linguistic rules requires a significant amount of time. Furthermore, NLP rules cannot keep up with the growth of language. The Internet has corrupted conventional English language standards. And no static NLP program can account for every irregularity typo on social media.
Early text mining systems relied exclusively on rules and patterns. As natural language processing and machine learning techniques have advanced, a growing number of organizations now provide solutions based solely on machine learning. But, as previously said, both techniques have significant downsides.
Video url;https://youtu.be/ENLEjGozrio?feature=shared
Hybrid Machine Learning Systems for NLP
The new hybrid text analysis tools rely on patterns and rules. When a new language is added, coding begins in accordance with the language's patterns and norms. The rules are then used by both supervised and unsupervised machine learning models to construct classifiers. The use of variants on this approach for low-, mid-, and high-level text functions.
Low-level text functions are the initial processes that run any text input. These routines represent the initial stage in converting unstructured text into structured data. They serve as the foundation for the information used by mid-level functions. Mid-level text analytics functions include extracting the true content of a piece of text. This refers to who is speaking, what they are saying, and what they are discussing.
The High-level text functions are the final stage, in which sentiment analysis is to determine and apply sentiment at the entity, topic, and document levels.
Low-Level:
Tokenization: ML + Rules
PoS Tagging: Machine Learning
Chunking: Rules
Sentence Boundaries: ML + Rules
Syntax Analysis: ML + Rules
Mid-Level:
Entities: ML + Rules to determine “Who, What, Where”
Themes: Rules “What’s the buzz?”
Topics: ML + Rules “About this?”
Summaries: Rules “Make it short”
Intentions: ML + Rules “What are you going to do?”
Intentions uses the syntax matrix to extract the intender, intendee, and intent
We use ML to train models for the different types of intent
We use rules to whitelist or blacklist certain words
Multilayered approach to get you the best accuracy
High-Level:
Apply Sentiment: ML + Rules “How do you feel about that?”
Summary
Language is chaotic and complicated!!!!. Meaning changes depending on who is speaking and who is listening. Machine learning may be an effective method for evaluating text data. In fact, it's critical; strictly rules-based text analytics is a dead end. However, simply using one sort of machine learning model is insufficient. Some parts of machine learning are highly subjective.
!!! You must tweak or train your system to reflect your viewpoint !!!.
In Conclusion;
The best way to do machine learning for NLP is a hybrid approach: many types of machine learning working in tandem with pure NLP code.



Comments
Post a Comment